Forged Calamity: Benchmark for Cross-Domain Synthetic Disaster Detection in the Age of Diffusion
Trong Le Do1,2 Mai-Khiem Tran1,2 Vinh-Tiep Nguyen2,3 Tam V. Nguyen4 Isao Echizen5 Minh-Triet Tran1,2 Trung-Nghia Le1,2†
1 University of Science, VNU-HCM, Vietnam • 2 Vietnam National University, Ho Chi Minh, Vietnam
3 University of Information Technology, VNU-HCM, Vietnam • 4 University of Dayton, USA • 5 National Institute of Informatics, Japan
* Equal contribution † Corresponding author

Abstract
The rapid advancement of text-to-image diffusion models has enabled the creation of highly photorealistic synthetic images that closely resemble real photographs, making it increasingly difficult to distinguish authentic content from AI-generated fabrications. This poses challenges for cybersecurity, digital forensics, and disaster response, where fake imagery of floods, fires, or earthquakes can spread misinformation or disrupt emergency operations. To address this, we introduce Forged Calamity, a benchmark dataset for synthetic disaster detection containing 30,000 images, including 6,000 real and 24,000 synthetic samples generated by four diffusion models. Comprehensive experiments across fine-tuned and zero-shot settings reveal consistent weaknesses in current forensic approaches. Fine-tuned detectors perform well in-distribution but lose up to 50% accuracy on unseen generators or disaster types, showing overfitting to model-specific artifacts. Zero-shot generalized detectors also struggle to maintain stable accuracy, with only limited resilience in a few representation-robust models. These findings highlight persistent generalization gaps and the urgent need for domain- and model-agnostic detection methods.
Forged Calamity Dataset
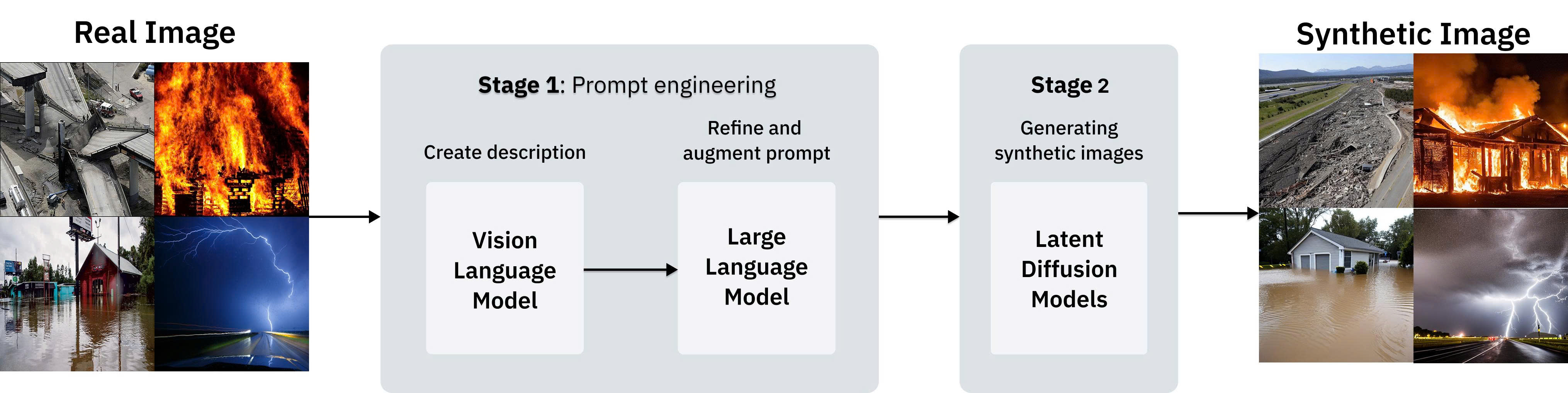
We developed a robust two-stage pipeline to ensure high-quality synthetic data:
- Prompt Engineering: Real-world disaster scenes are transformed into optimized textual descriptions using Moondream and Llama 3.
- Image Synthesis: High-fidelity samples are generated across four diffusion models: SD 1.5, 2.0, XL, and PixArt.
Then, a similarity filtering mechanism is applied to ensure high visual diversity and eliminate redundancy across all disaster categories.
The Forged Calamity dataset consists of 30,000 images across four disaster categories: Fire, Earthquake, Flood, and Thunderstorm.
- Real Images: 6,000 images curated from Incident-1M and the internet.
- Synthetic Images: 24,000 images generated using four state-of-the-art diffusion models: Stable Diffusion 1.5, Stable Diffusion 2.0, SDXL, and PixArt.
- Diversity Filtering: To eliminate redundancy and ensure high visual diversity, we applied a similarity filtering mechanism proposed by Nguyen et al., removing highly similar generated samples.
| Disaster Category | Real Image | Synthetic Image (Generators) | |||
|---|---|---|---|---|---|
| SD 1.5 | SD 2.0 | SD XL | PixArt | ||
| Fire | 1,500 | 1,500 | 1,500 | 1,500 | 1,500 |
| Earthquake | 1,500 | 1,500 | 1,500 | 1,500 | 1,500 |
| Flood | 1,500 | 1,500 | 1,500 | 1,500 | 1,500 |
| Thunderstorm | 1,500 | 1,500 | 1,500 | 1,500 | 1,500 |
| Total | 6,000 | 24,000 | |||

Benchmarking Protocols
Our evaluation focuses on the Out-of-Distribution (OOD) generalization capacity of forensic models, simulating real-world scenarios where detectors encounter unseen disaster types or new generative technologies. This setup is designed to determine whether a model learns generalizable artifacts of synthesis or merely overfits to specific model "fingerprints."
We evaluated the generalization capacity of forensic models by training on a single domain (Earthquake generated by SD 1.5) and testing on unseen domains (Fire, Flood, Thunderstorm) and unseen generators (SD 2.0, SDXL, PixArt).
Results
We present the cross-generator accuracy of models trained on Earthquake (SD 1.5) and tested on unseen generators (PixArt, SD 2.0, SD XL). Red indicates the best result, Blue indicates the second best, and Green indicates the third best.
1. Standard Classifiers (Fine-tuned)
| Method / Test Set | PixArt | SD 2.0 | SD XL |
|---|---|---|---|
| ConvNeXt | 36.13 | 21.08 | 35.87 |
| Swin | 79.17 | 82.98 | 70.48 |
| ViT | 82.79 | 95.11 | 64.57 |
| SigLIPv2 | 68.57 | 76.19 | 84.19 |
| DINOv2 | 89.02 | 97.46 | 88.00 |
| ResNet152 | 52.06 | 79.17 | 45.02 |
2. Deepfake Detectors (Fine-tuned)
| Method / Test Set | PixArt | SD 2.0 | SD XL |
|---|---|---|---|
| RINE | 93.33 | 81.33 | 83.70 |
| UA | 85.84 | 92.89 | 92.57 |
| LGrad | 69.84 | 94.35 | 89.40 |
| DIRE | 49.27 | 64.89 | 45.02 |
| FreqNet | 1.59 | 25.52 | 16.63 |
| ADOF | 89.02 | 67.05 | 92.76 |
| CGL | 82.73 | 11.05 | 88.44 |
3. Zero-shot Generalized Detectors
Tested on Earthquake images generated by various models (No fine-tuning).
| Method / Test Set | SD 1.5 | PixArt | SD 2.0 | SD XL |
|---|---|---|---|---|
| UniFD | 9.10 | 2.10 | 0.30 | 4.00 |
| DAE | 64.70 | 67.75 | 100.00 | 68.38 |
| SPAI | 100.00 | 70.98 | 92.06 | 98.86 |
| FatFormer | 27.62 | 5.97 | 4.83 | 23.81 |
| ADOF (Zero-shot) | 99.81 | 99.17 | 97.78 | 99.94 |
| CGL (Zero-shot) | 87.62 | 82.73 | 11.05 | 88.44 |
Citation
Acknowledgements
This research is funded by Vietnam National University - Ho Chi Minh City (VNU-HCM) under Grant Number C2024-18-25. This research used the GPUs provided by the Intelligent Systems Lab at the Faculty of Information Technology, University of Science, VNU-HCM.